

21 Dec AI for Fake Charities recognition: discovering terrorism funding
To enrich the capabilities of the system towards the scopes required Expert.ai has led an experimentation for exposing fake charities destined to terrorism, through a hybrid computational stylometry/machine learning approach. The objective is to discern between true and fake requests of charity.
In order to apply machine learning algorithms, vast and tagged corpora are required for the training phase of the algorithms themselves. To date, corpora like these are not available on the internet. The choice then fell on a big repository of fake news containing more than twenty-one thousand documents tagged as reliable or unreliable. They were organized in a .csv file, where each documents had an ID, a title, an author, a text, and a label (“1” for “reliable” and “0” for “unrealiable”).
Starting from this .csv file, which was converted into an excel table, a work of pre-processing was made: documents with missing cells were discarded, as well as documents whose language was not English. The final number of documents retrieved was then 20369. Then, an ad-hoc parser was built in order to extract all the texts from the excel file. For each one of these, a corresponding .json and .txt file have been generated. Also, during the parsing phase, texts have been enriched with metadata as document source, document type and language, and finally they have all been indexed in Elasticsearch. After this preliminary phase, the Computational Stylometry with its 204 stylometric indexes analysed the texts. The results were taken and used to build the .arff files required by the Machine Learning engine. The ML method of analysis chosen was a supervised one, the so-called cross validation: this means that the system was trained with a selected sub-dataset of the whole corpus indexed, and then tested with another sub-dataset. The .arff files covered the roles of training set and test set. The training set contained 6000 documents, while the test set contained 2000.
The results obtained through the application of several algorithms are displayed in Table below:
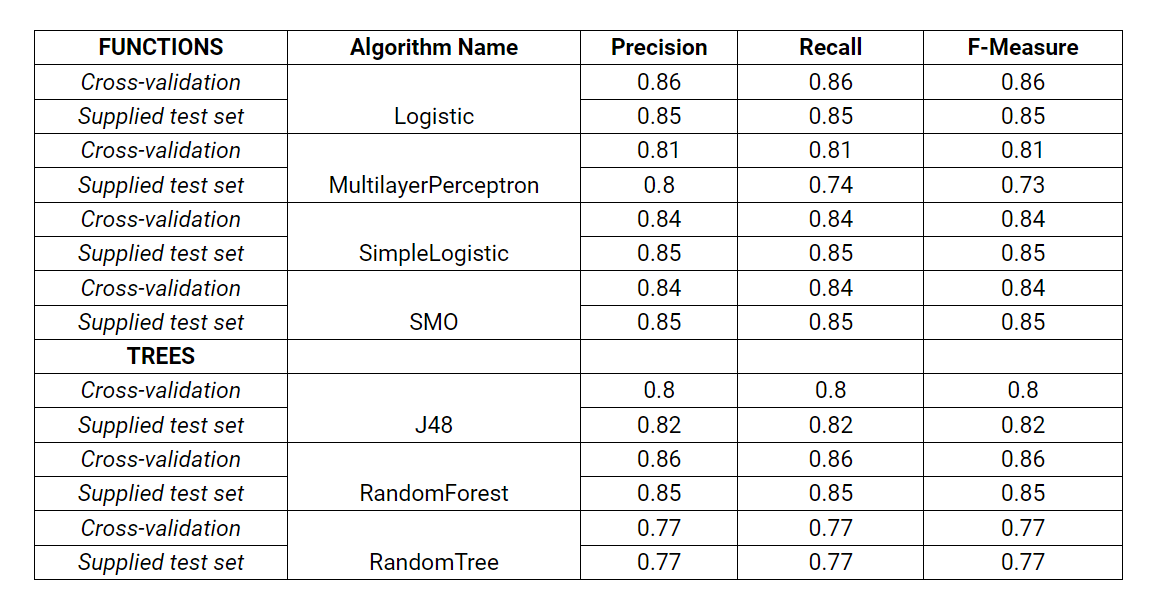
The algorithms which returned the best results are Logistic, SimpleLogistic, and RandomForest, with a brilliant 85% F-score.
Thanks to these encouraging results, a dedicated service for Fake Charities has been developed: it accepts texts in input and returns a “reliable” or “unrealiable” output as its evaluation of the given text.
This could be a very useful and empowering functionality for the whole project: by filtering websites on which requests of funding can be found, through this service, the ANITA end users will be able to discover which ones are reliable, and which ones not, thus exposing fake charities.
Experimentation using Deep Learning
Exploiting twelve thousand files of the same corpus described previously, and the same stylometric features, a further experimentation has been led using Deep Learning instruments.
A neural network has been designed: 4 hidden layers have been used, for a total of 27146 parameters all trainable. The neural network has been trained with 10200 documents, and after 100 Epochs the result on the training set has been the following:
Epoch 100/100
10200/10200 [==============================] – 0s 6us/step – loss: 0.3622 – accuracy: 0.9137
The actual test has then been made on the remaining 1800 documents. The final results on the test set are:
1800/1800 [==============================] – 0s 24us/step
[loss: 0.376337448226081, accuracy: 0.9133333563804626]
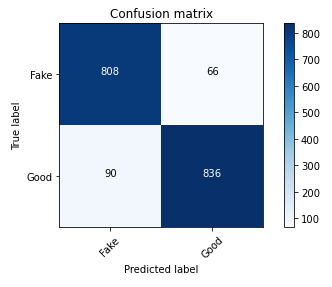
The confusion matrix obtained is shown in Figure below:
Conclusions
Both of the experimentations have been performed by using a unique dataset annotated with reliable/unreliable values. Dataset has been split in training and test sets; for this reason, high values of results in terms of precision and recall in the testing phase are also dependent on the same nature of the data. When other datasets are tested, precision and recall could suffer some decreasing. In order to make more resilient the models, the training phase can be improved by combining different datasets coming from various origins and sources.
Author: Ciro Caterino, Expert.ai