

11 Jan Stylometric Analysis and Machine Learning: a winning couple for Authorship Identification
Stylometric Analysis
Stylometryc Analysis aims at analysing the key traits of a text in terms of vocabulary use and writing style which can help to identify the author, or some information related to their profile, such as gender and age. These traits are called linguistic features, whose collection and gathering conducted by statistical and computational methods can outline the Authorial DNA, namely the unique writing style of an author (as unique as the fingerprint) defined by the set of the characteristics of their language, which originate from psychological and sociological properties and peculiarities. Indeed, variation in psychological and sociological aspects of the author define a stylistic variation. These psychological factors include personality, mental health, and being a native speaker or not; sociological factors include age, gender, education level, and region of language acquisition (Daelemans, 2013). Some of the linguistic features relevant for stylometric the analysis are: frequency of n-grams (sequences of n letters/syllables/words), frequency of punctuation markers, frequency of errors, average length of sentences, frequency of repetitions, richness of vocabulary, terminology choices, the use of punctuation marks and so on (Oakes, 2014).
The approach to Computational Stylometry adopted is essentially simple: to provide a platform that analyzes any written document in order to predict a few unknown traits about the writer. As a whole, such a system functions as an author profiling platform, where the end user submits target documents and queries the system for predictions about one or more unknown author’s traits of interest (among the ones actually supported by the system itself): identity, age, gender, and so on.
This problem of author profiling has been modelled with a combined approach that leverages the power and flexibility of NLP, and the added support of machine learning (ML) techniques. This approach focuses on flexibility and expandability: in the first version, the system will be able to extract a starting set of stylometric measures (to be fed as input to the ML algorithm) from documents and use it to predict an initial set of author’s traits (namely identity, age, and gender). Anyway, the platform will enable continuous update and improvement of the measure set, and support of new traits.
Experimentation using Machine Learning: Arabian Terrorists Authorship Identification
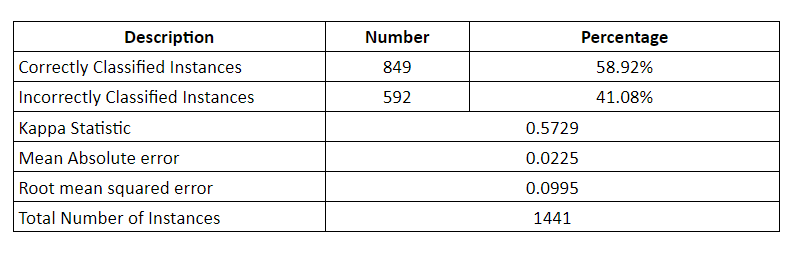
A specific use case has been implemented thanks to the exploitation of a set of provided documents coming from transcript audio files. The set consists of 5700 documents, tagged with the author information, gathered in 60 sets, one for each author. In the table below are shown the results of an experiment based on the whole set, with 4259 documents as Training set and 1441 documents as Test set.
The results obtained through the application of several algorithms are displayed in Table below:
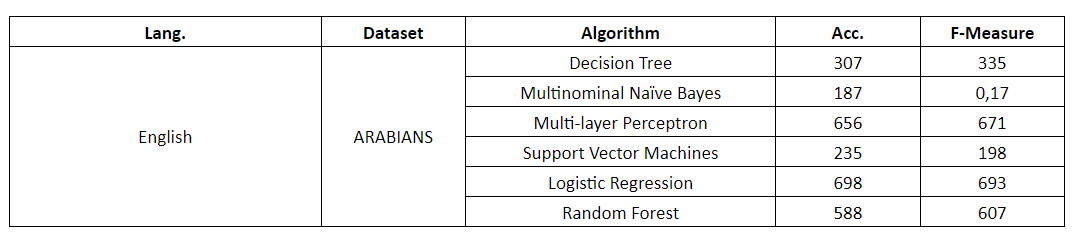
Terrorist Authorship Identification
experiment (60) SF-103 Accuracy 59% -> SF-204 accuracy 69,8 % +10,8%
Explanation of the value of the accuracy
As demonstrated by (Koppel et al., 2010), performance decreases when the approach is applied to a large set of candidate authors. Obviously, their approach involved thousands of candidates. Another important point of reference in authorship attribution with a large set of candidates is represented by the study carried out by (Argamon, 2003). In fact, in their study the scholars dealt with a set of Usenet posts, including the two, five, and twenty most active authors. Increasing author set size from two to twenty led to a performance drop of 40%. (Grieve, 2007) also shows a significant decrease in performance when increasing author set size from two to forty authors. (Luyckx, 2011) measure the influence of author set size in three evaluation data sets (one is single topic and two are multi-topic). This kind of sets allow the scholars to investigate the effect in differently sized data sets in terms of author set size, data size, and topics. Increasing the number of candidate authors leads to a significant decrease in performance. This effect is visible in all three data sets, regardless of their size, the language they are written in, and the number of topics. Analyzing the first dataset, the accuracy drops considerably while the set of authors increases. In authorship attribution with two candidate authors they achieve an accuracy of about 80%, with five candidates it drops to 70% and so on to 145 candidate authors can be done with an accuracy of around 11%, which was deemed rather good and also nowadays this work can be considered a landmark for authorship attribution in the case of a large set of candidates.
It should be considered the additional difficulty that the use case we have reported in the previous table is related to documents coming from transcript audio files. An ambitious approach on which not many studies are reported in literature, and in these few works the average number of candidate authors was below ten. It is also known that the speech style is different from the writing style. (Airoldi, 2006) conducted interesting research in order to recognize who wrote Ronald Reagan’s radio addresses. In a set of 1062 radio speeches, the scholars attributed 679 speeches to Ronald Reagan and 39 to his collaborators (12 to Peter Hannaford, 26 to John McClaughry, and 1 to Martin Anderson). The authorship of the remaining 312 speeches remained uncertain. A similar experiment has been carried out by (Herz, 2014) that investigated the authorship of Barack Obama’s speechwriters on a corpus composed of thirty-seven speech transcriptions. They based their research on the supposition that Barack Obama has four principal speechwriters and dealt with the authorship attribution of Barack Obama’s speeches with four different approaches, that reached different results, but still showing that computational stylometry can be used to differentiate authors who write in a similar style.
The research is based on a set of 60 authors with an average of 100 texts for each author. The average length of texts is 2000 characters circa. Considering the corpus of transcripts and considering the performances achieved in the researchers reported in this document, performances can be considered very good. This is confirmed by the test based on just seven authors, in which texts have been correctly classified for 6 out of 7 authors.
It has been selected seven of these sixty authors and renamed them with the nickname “Person”. This corpus of transcriptions contains 117 documents gathered in 7 sets (one for each author), and each one of them has been used to train classifiers of the Stylometry Analysis Service to recognize their own style and to discern one from each other.
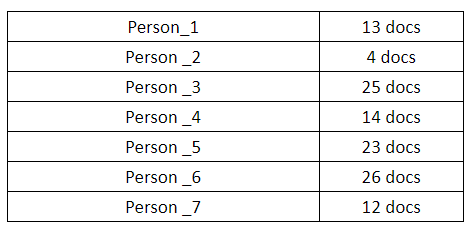
The algorithm which gave the best performances was Multilayer Perceptron. Its adequateness has been calculated by means of Precision (percentage of relevant instances among the retrieved instances, also defined as success in prediction), Recall (percentage of the relevant instances that have been retrieved over the total amount of relevant instances), and F-Measure (the harmonic mean of precision and recall).
These values have been estimated thanks to a process of cross-validation.

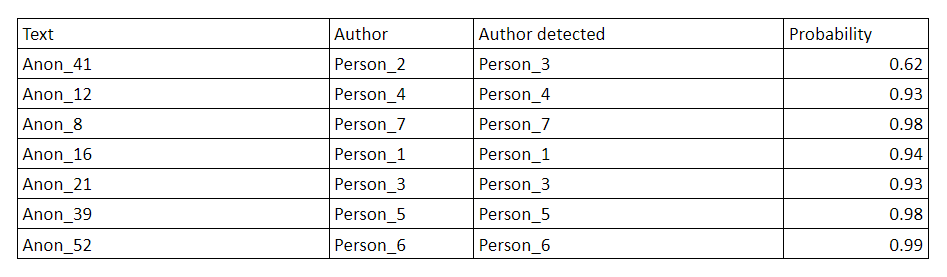
As it is possible to observe, performance has been improved: the less the number of authors decrease, the better the performances. The table below shows the last experiment. For each “Person”, one text has been selected randomly. The table shows the percentage of probability that the authorship attribution is correctly done.
Author: Ciro Caterino, Expert.ai
Bibilography:
Airoldi, E. M., at al (2006). Who wrote Ronald Reagan’s radio addresses?. Bayesian Analysis, 1(2), 289-319.
Daelemans, W. (2013), Explanation in Computational Stylometry. Conference: Proceedings of the 14th international conference on Computational Linguistics and Intelligent Text Processing – Volume 2
Oakes, M. (2014) “Literary Detective Work on the Computer”, in the Series “Natural Language Processing, no. 12″, p. 283, Amsterdam: John Benjamins Publishing Company
Koppel, M., et al (2010). Authorship attribution in the wild. Language Resources and Evaluation. Advanced Access published January 12, 2010:10.1007/s10579-009-9111-2.
Argamon, S., at al (2003). Style mining of electronic messages for multiple authorship discrimination: First results. Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Washington DC: Association for Computing Machinery, pp. 475–80.
Luyckx, K., (2011). The effect of author set size and data size in authorship attribution. Literary and linguistic Computing, 26(1), 35-55.
Herz, J., & Bellaachia, A. (2014). The authorship of audacity: Data mining and stylometric analysis of barack obama speeches. In Proceedings of the International Conference on Data Mining (DMIN) (p. 1). The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp).